
Deep Learning is a hot-topic currently, but there is a good bit of confusion over what is means, and how much relevance it has commercially.
In this article I want to run through what deep learning is, why it is such a good idea (I’m a fan) and indicate some of the promising directions it’s taking. AI’s oversold claims in the past have made people suspicious of the space, and the ‘Intelligence’ tag often raises wariness of over-hype. So this time around, is there more substance and less smoke?
Deep Learning is rapidly becoming part of the mainstream tech ecosystem - everyone with an eye on industry trends needs to be aware of its impact. Google CEO Sundar Pichai has announced that deep learning is a core transformative way by which Google are rethinking everything they do.
There is a wealth of material readily available on the web covering Deep Learning, but a lot descends rapidly into the maths and discussions on competing algorithms. Here I want to present a higher-level overview of Deep Learning, but also describe some practical applications of where moving approaches out of the research environment can give real competitive advantage - areas such as image recognition and pattern extraction from large unstructured data-sets.
The term AI was first used way back in a research proposal written in 1955, which suggested that machines could “solve the kinds of problems now reserved for humans…if a carefully selected group of scientists work on it together for a summer”. (Optimism in tech estimates isn’t new!)
AI unfortunately became known for promising much more than it delivered. People working in universities came to view AI as a risky research area, preferring to discuss “learning systems”, “expert systems” or “neural networks”. Even after a measure of rehabilitation the term ‘AI’ isn’t championed of itself. Instead, new labels such as Deep Learning have taken over.
Deep learning is a child of the area of artificial intelligence known as neural networks, a space for a long time confined to niche research groups and academia.
In the late eighties and nineties, AI and Neural Networks showed enormous early promise as a field. People talked of simultaneous translation, real-time image recognition and AI driven robotics. Research groups emerged, and funding was raised. Unfortunately, the field hit hard barriers very fast. Some of them were the early state of the processing technology at the time and others due to unrealistic extrapolation from early experiments.
In the end the AI field mostly languished for a good 10 years – a period referred to as the ‘AI-winter’.
That all started to change in the late 2000’s.
Moore’s Law caught up with the needs of Neural Networks. Companies like Nvidia began delivering scarily fast GPUs (chips originally designed for heavy duty number crunching to support fast image rendering in games) that finally gave developers the compute power they needed. The advent of GPUs suddenly meant that the time training a system dropped by orders of magnitude. A complex (3-4 layer) deep learning network, which could have taken many weeks of CPU time previously could now complete its computations in hours.
Big Data arrived – with vastly increased storage and tool-sets for manipulating data at volume. A vast wealth of new data became available to allow networks to be trained and performance benchmarked.
Algorithms improved, after years in the wilderness many of the problems previously thought intractable could now be tackled. With the emergence of a critical mass of key thought-leaders in the space, (people including Geoffrey Hinton of Google, Andrea Ng of Baidu and Demis Hassabis of DeepMind) algorithms got better really fast. Suddenly machine learning had a new set of standard bearers and a new approach to rally behind - Deep Learning.
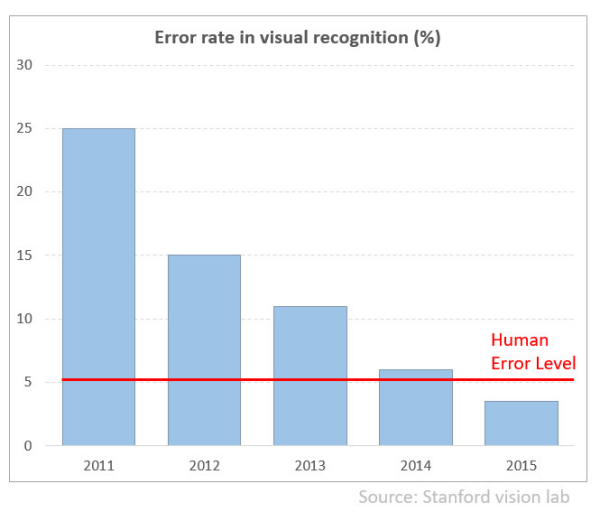
ImageNet was a database of images, all labelled by hand. For any given word, such as “horse” or “dog”, ImageNet contains hundreds of images. The annual ImageNet contest encouraged people to compete and measure their progress in getting computers to automatically recognize and label images. Their systems were trained using a set of labelled images and then given the challenge of labeling previously unseen test images. In 2010 the best performance was 72% correct (humans get it right 95% of the time). In 2012 one team, led by Geoff Hinton, achieved 85% accuracy, due to a new approach called Deep Learning. Further enhancements ensued and by 2015 reliably hit 96% accuracy - surpassing humans for the first time. This is a really significant milestone.
Word spread quickly about the accuracy level - Deep Learning crossed the tipping point from interesting research to commercially very important. Funding poured into the sector and more and more complex deep learning systems were developed, from a couple of layers at the beginning to ones utilizing hundreds.
As the classification power of the networks improved, the ability to create better abstractions enabled the range of problems domains they could work in to expand. Medical imaging, handwriting recognition, video search, image reconstruction, self-driving vehicles.
By 2012 Deep Learning as a concept had crossed the Rubicon. The breakthrough was in recognizing that lots of existing techniques could be combined in new ways, coupled with the enormous firepower of new high-performance hardware to handle the vast data sets needed to train the systems up-front. Note that the intelligence is emergent from the whole system, each element is pretty dumb in itself, but the combination produces a very smart system.
It’s important to understand some of the terminology. First-off, Neural Networks. At the simplest level, Neural Networks are about doing lots and lots of basic pattern matching operations over a set of data using a small ‘mask’ (called a kernel or filter) to look at a small subset of the data set at a time. The outputs from combining the input data and the kernel are fed into further repeated steps. The end output is then analyzed to see if the results are good and modifications are made to the kernel parameters if needed, and the process repeated. Lots of CPU cycles and lots of storage space are required to get meaningful output.
The ‘neural’ term comes from the way the system mirror the way neurons in the human brain work. The inputs from say the human visual system, (a large source data set), feed into neurons, which trigger the activation of other neurons with some paths having greater preference (‘weight’) so their signals making a larger contribution to the output, which in turn is fed into another layer.
The label Deep Learning is ‘deep’ in the sense that the systems use a cascade of many layers of (nonlinear) processing systems. Each successive layer uses the output from the previous layer as input.
By the way the term Convolutional in neural networks just refers to the mathematical way of combining (convoling) two signals to form a third signal. You can find a nice visual explanation here.
In the abstract the convolution layer is the feature detector that removes information in the input data that is not needed using a convolution mask.
The Pooling layer down-samples the output from the convoluted layer to reduce the dimensionality – this preserves most important information but reduces the size.
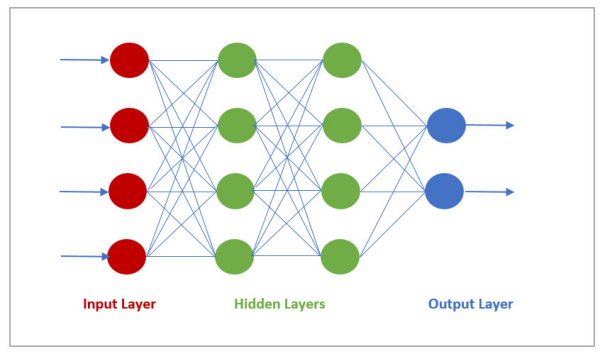
Typically a neural network is organized into layers. The inputs are fed into a series of layers which combine them with weightings before passing to the next layer. The more layers the ‘deeper’ the network and the more abstract the detection can be. Training the network is done by iterative changing the weights given to signals at each level so that the outputs meet a certain threshold for given inputs. Note the middle layers are only termed hidden as their output is connected only to other inputs and therefore not visible as a network output.
In artificial neural networks this is mirrored in software (and hardware), where the mask is actually a mathematical function (activation function) which enhances or diminishes the influence of input source data on the outputs. This processing happens many times with the output from one stage feeding the next. The overall goal is to achieve some pre-determined threshold of error in the end output that is acceptable (usually a gradient descent approach). This could be the errors rate in machine translation compared to human samples, image classification and tagging benchmarked against a set of pre-tagged data or defects in some manufacturing process that needs classification.
This trial-and-error process is slow, and the network can fall into the problem of local minima (this is like a climber scaling a mountain in fog, getting to a peak and thinking they are at the mountain summit when they aren’t). Techniques to solve this have been developed. There are a number of activation functions (the kernel) that people use, but the best and dominant one currently is ReLU (a non-linear function, others sometimes used include sigmoid and softplus) – for hidden layers it is much faster, better than logistic functions and resolves the gradient vanishing problems that the others hit.
The training process for a neural network is iterative. Typically we begin with some sample data. We pass this forward through the neural network to get predictions. We calculate the errors in these predictions and ‘back propagate’ the errors to update the connection weights in the network to improve the predictions. This iteration is continued until the error rate is below some pre-determined threshold.
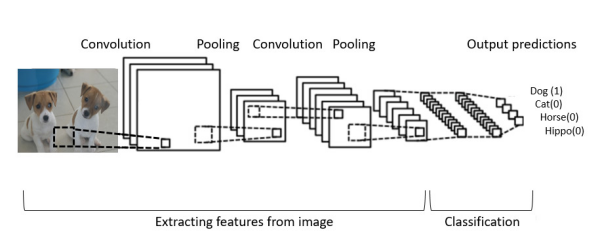
Convolution neural networks were originally (largely) inspired be looking at how the human visual system works, and the layers of intermediate processing that happens before the brain recognizes what we see as an object. CNN’s have multiple layers of transformation which are applied one after the other to extract increasingly sophisticated representations of the input so that it can be accurately classified (other otherwise used).
Digging down a bit into details of the processing steps to identify the puppies in the above image, the following is a simplified model of the training process for the network:
A: We initialize all parameters / weights with random values
B: The network takes a training image as input, goes through the forward propagation step (convolution, ReLU and pooling operations along with forward propagation and finds the output probabilities for each class.
C: Calculate the total error at the output layer (summation over all 4 classes of the target probability minus the output probability.
D: Use Back-propagation to calculate the gradients of the error with respect to all weights in the network and use gradient descent to update all weights and parameter values to minimize the output error.
- The weights are adjusted in proportion to their contribution to the total error.
- When the same image is input again, the output probabilities may now be closer to the target
- If so this means that the network has learnt to classify this particular image correctly by adjusting its weights / filters such that the output error is reduced.
- If not, the parameters were a bad choice, we need to adjust them and iterate again
- Parameters like number of filters, filter sizes, architecture of the network etc. have all been fixed before Step 1 and do not change during training process – only the values of the filter matrix and connection weights get updated for simplicity.
E: Repeat steps 2-4 with all images in the training set. This can take a long time depending on the resource set
This is the process to just train the network – in the end we (hopefully!) have all the weights and parameters of the network are optimized to correctly classify images based on the training data.
When a new (brand new) image is provided, the network goes through the forward propagation step and output a probability for each class using the weights determined in the training stage. If the training set is large enough, the network will generalize to new images and classify them into the correct categories.
What really got people excited about this field was when they realized is that this one technique, deep learning, can be applied to so many different domains.
Deep learning comes in different flavors. The most common approach is called supervised learning, a technique that can be used to train a system with the aid of a labelled set of examples. For image recognition, you can use massive online stores of images which are already labelled. A deep-learning system can be trained using this source image set – the process involved repeatedly iterating the system adjusting the activation weights within the network until an acceptable error level is reached.
The immediate advantage of this approach is that there is no need for a person to create the rules or a programmer to code the business logic for the classification. The system doesn’t ‘know’ what the data means, it is just looking to optimize some utility function through shaking up the weighting parameters and seeing if the output is an iterative improvement from the last arrangement (by checking the gradients of error).
The disadvantage is that you need lots of training data from the get-go. If you don’t have it, this approach isn’t going to do much for you.
But in domains with lots of existing data, these systems are excellent for classification – e.g. fraudulent banking transactions, flagging spam email, tagging photos and videos, giving people a credit score, finding mineral deposits, deciding if a person matches a passport photo. There is a huge pool of available data which can be exploited to create accurate systems.
The other major type of deep learning is termed unsupervised learning. Here there isn’t an upfront training data set and the desired outcome (the error function that needed minimizing) is poorly unknown. Unsupervised learning is strong in areas such as pattern searching when you don’t know what the pattern might be in the beginning. Strange patterns of logins on a site, radio chatter from suspects in a conflict zone, network attacks being set-up – all are areas actively using unsupervised learning.
In one famous instance, Google ran a project (Google Brain) where a massive unsupervised learning system was tasked to seek common (but not known or suspected) patterns in unlabelled YouTube videos. After crunching images for many days one of the students called his manager to show the output. On the screen was an image of a cat, distilled down from all the source videos. This may seem trivial (or expected on the web!) but important to remember is that this system didn’t know what it was looking for – it discovered an image trend itself, without training or supervision from its human programmers.
In between supervised and unsupervised learning sit the hybrid approach of Reinforcement Learning. It involves training a neural network to interact with an environment with limited feedback. DeepMind (part of Google) is a specialist in this area. In 2015 it built a reinforcement system to play a range of classic Atari video games, using just the on-screen pixels and the game score as inputs. The system learned to play them all and achieved human-level performance (or more) in over half.
DeepMind achieved a watershed and made headlines worldwide when its AlphaGo system defeated Lee Sedol, one of the world’s best Go players, by 4-1 over a five-game series. Like the Atari game player, AlphaGo is a reinforcement-learning system. It consists of several discrete modules, including two deep learning engines, each of which specializes in a different thing—analogous to the human brain. One of them has been trained on game play to suggest interesting game moves. The second DL engine rates the moves for strategy value using by random sampling. This hybrid system points to a key direction in DL, specialization and modularization of functions which are then chained to create system which are much more powerful (intelligent) than general purpose DL systems.
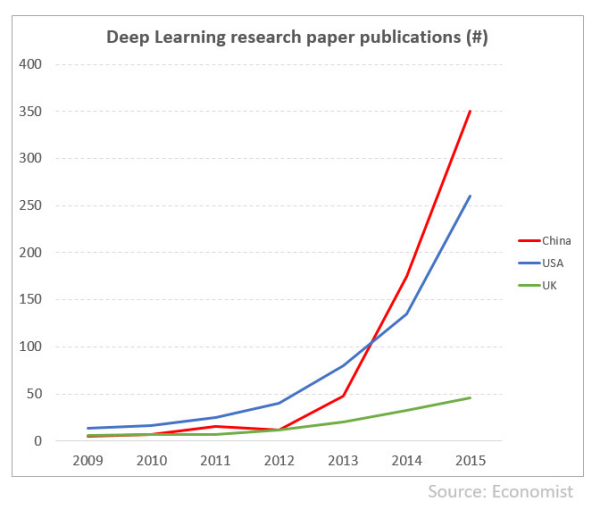
Lots of hype ensued around the Go-event (including people suggesting that the Skynet takeover or the singularity were imminent). This time around however AI could show a real and meaningful barrier had been reached. The funding gates opened and a rapid brain drain began in earnest from academia to industry. China began investing heavily and currently produces more research publications than the US.
But deep learning is different - it actually works, and people are using it everyday without realizing it. The long-term goal researchers aspire to is to build a general artificial - a system capable of solving a range of tasks—rather than building a new system for each problem (cars, handwriting, or credit-card fraud say). Since its inception AI research has focused on solving specific, narrow problems but at least the first steps on the path the generalized problem-solving systems are now being taken.
Google, Facebook, Microsoft, IBM, Amazon, Baidu and others have made much of their deep-learning software available freely as open-source and this forms an excellent resource for anyone interested in the field.
One of the big winners in the Deep Learning space is Nvidia, as just about every company in the space is using its GPUs to train their networks. GPU capacity can also be rented in the cloud from Amazon and Microsoft. IBM and Google, meanwhile, are devising new chips specifically built to run AI software more quickly and efficiently. Nvidia’s new Pascal GPU architecture will accelerate deep learning applications even more (potentially tenfold) beyond the current generation Maxwell processors.
Humans can learn from modest amounts of data, which “suggests that intelligence is possible without massive training sets”. Startups need to look at less data-hungry approaches to AI.
The approach in Deep Learning is still very much brute force (even without training, it burns a lot of CPU cycles). Humans on the other hand are able to use short-cuts which prune the process of both learning and classification though intuition and heuristics. People are also able to learn from very modest amounts of data and our decision-making processes have been tuned over millennia. Deep Learning provides a pretty elegant approach but ultimately it will require much more refinement and research to advance to more general-purpose AI.
Future areas that show great potential are next generation learning systems – systems that go beyond the current mainstream paradigm of training-learning (i.e. with large initial data sets to learn from) to self-learning-training through feedback (where there aren’t initial data sets) and the next phase again which is the ability to learn new mechanisms of learning itself, looking at agent based neural models. This is a hard challenge as our knowledge of how the brain actually creates heuristics is scare, and our models of cognitive processes are still basic. Please browse other articles in our resource area for additional information.